Je trouve l’entropie extrêmement fascinante. Cependant, faire le lien entre la formule et ses explications “intuitives” concernant les codes préfixes et le contenu informationnel n’est pas évident. Ici, je souhaite passer en revue quelques manières d’aboutir indépendamment à cette idée.
Propriétés de l’information
Supposons que nous voulions définir une fonction , qui représente la quantité d’information d’un événement. En faisant abstraction des spécificités de l’événement, une mesure que nous pourrions utiliser pour comparer un événement à un autre est leur probabilité d’occurrence. Ainsi, pourrait être une application d’une probabilité vers . Dans ce cadre, les exigences suivantes sont raisonnables :
- . Si un événement se produit certainement, il n’est pas très intéressant et nous donne peu d’information.
- doit être continue et monotoniquement décroissante sur . Un événement plus commun est moins informatif.
- Deux événements indépendants de probabilités et doivent avoir une information
La dernière exigence est la plus révélatrice. Par définition, la probabilité que deux événements indépendants se produisent est . Donc
Puisque la fonction doit être continue, ceci n’est vrai que pour
Si nous voulons que soit monotoniquement décroissante,
doit être négative. Puisque est positif, doit être négatif. En posant
Puisque , où le dénominateur est une constante, nous pouvons considérer que encode la base du logarithme. Par commodité, nous posons , et nous laissons désigner le logarithme en base 2.
L’entropie est simplement l’espérance de , sur une distribution
Nous supposons également que , ce qui est justifié par la continuité.
Par exemple, considérons la variable aléatoire de Bernoulli , qui prend la valeur avec une probabilité , et avec une probabilité . Si nous traçons son entropie
Code de tracé
from pathlib import Path
import numpy as np
import plotly.graph_objects as go
# Function to calculate the entropy of a Bernoulli variable
def bernoulli_entropy(p):
return -p * np.log2(p) - (1 - p) * np.log2(1 - p)
# Generate values for p from 0 to 1
p_values = np.linspace(0.01, 0.99, 100)
entropy_values = bernoulli_entropy(p_values)
# Shared trace for both themes
trace = go.Scatter(
x=p_values,
y=entropy_values,
mode="lines",
name="Entropy",
line=dict(color="red"),
)
# Output directory (repo root/static)
output_dir = Path(__file__).resolve().parents[3] / "static"
output_dir.mkdir(parents=True, exist_ok=True)
themes = [
{
"template": "plotly_white",
"font_color": "#111111",
"axis": {
"linecolor": "#111111",
"tickcolor": "#111111",
"tickfont": {"color": "#111111"},
"title_font": {"color": "#111111"},
"showgrid": True,
"gridcolor": "rgba(17, 17, 17, 0.2)",
"gridwidth": 1,
"zeroline": False,
},
"filename": "bernoulli_entropy_plot_light.html",
},
{
"template": "plotly_dark",
"font_color": "#f5f5f5",
"axis": {
"linecolor": "#f5f5f5",
"tickcolor": "#f5f5f5",
"tickfont": {"color": "#f5f5f5"},
"title_font": {"color": "#f5f5f5"},
"showgrid": True,
"gridcolor": "rgba(245, 245, 245, 0.2)",
"gridwidth": 1,
"zeroline": False,
},
"filename": "bernoulli_entropy_plot_dark.html",
},
]
for theme in themes:
fig = go.Figure(data=[trace])
fig.update_layout(
title="Entropy of a Bernoulli Random Variable",
xaxis_title="p",
yaxis_title="Entropy",
template=theme["template"],
font=dict(color=theme["font_color"]),
paper_bgcolor="rgba(0, 0, 0, 0)",
plot_bgcolor="rgba(0, 0, 0, 0)",
xaxis=dict(showline=True, **theme["axis"]),
yaxis=dict(showline=True, **theme["axis"]),
)
fig.write_html(output_dir / theme["filename"])
nous voyons qu’elle est maximisée lorsque la distribution est uniforme, et minimisée lorsqu’elle est presque déterministe.
Codes préfixes
Supposons que nous ayons un ensemble de symboles que nous souhaitons transmettre sur un canal binaire. Nous concevons le canal de manière à pouvoir envoyer un ou un à la fois. Nous voulons trouver un schéma de codage optimal pour , avec une exigence : il doit être préfixe.
Définissons une fonction de codage , qui associe des symboles à des chaînes binaires de longueur . Nous disons qu’un codage est préfixe si aucun mot de code n’est le préfixe d’un autre. Par exemple, n’est pas préfixe car est un préfixe de . En revanche, l’est.
Un code préfixe implique que le code est uniquement déchiffrable sans délimiteurs supplémentaires entre les symboles, ce qui est une propriété souhaitable.
Nous remarquons également qu’un code binaire préfixe est uniquement défini par un arbre binaire :
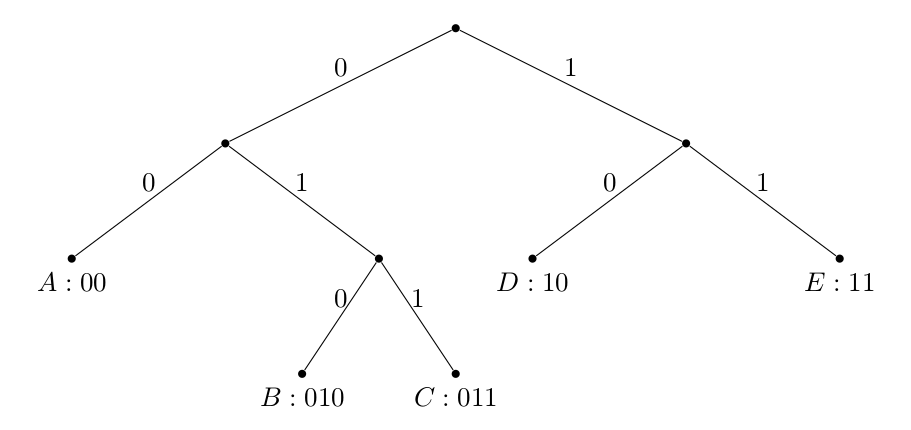
où le chemin de la racine au symbole détermine le mot de code, et les symboles sont toujours des feuilles. Assurez-vous que toute construction de ce type aboutit à un code préfixe.
Nous allons maintenant montrer que la longueur moyenne d’un mot de code de tout code préfixe sur est bornée par
où est une variable aléatoire prenant des valeurs dans l’ensemble avec des probabilités . Plus important encore, nous voyons que l’entropie de est une limite inférieure pour le degré de compression d’une distribution, ou de manière équivalente, pour la quantité d’information qu’elle contient.
Inégalité de Kraft


Supposons que soit la longueur du ème mot de code. Si le code est préfixe :
Preuve :
Soit la longueur du mot de code le plus long. On remarque que :
- Il y a au plus nœuds au niveau
- Pour tout mot de code de longueur , il y a descendants au niveau .
- Les ensembles de descendants de chaque mot de code sont disjoints (puisqu’un mot de code n’est jamais le descendant d’un autre)
Cela implique
Pourquoi au lieu de l’égalité ? Parce qu’il est possible qu’un nœud au niveau ne soit le descendant d’aucun mot de code (considérez l’arbre du code ) !
Borne inférieure pour L
Maintenant, considérons la longueur moyenne du mot de code
Nous allons montrer que l’entropie est une borne inférieure pour , soit
Démonstration :
Où la dernière inégalité est due à 1) la divergence de KL étant non négative et 2) à en raison de l’inégalité de Kraft. Une chose à noter est que si , alors , le minimum théorique. La raison pour laquelle nous ne pouvons pas toujours l’atteindre est que n’est pas nécessairement un entier, ce qui est évidemment requis.
Une borne supérieure pour L
Remarquez qu’il est possible de construire un code préfixe avec les longueurs
puisqu’elles satisfont l’inégalité de Kraft :
Par la définition de la fonction plafond
En prenant l’espérance sur , on obtient
Cela montre que est une bonne borne supérieure pour L !
En résumé, l’entropie est une borne inférieure, et une estimation raisonnable, pour le nombre moyen de bits nécessaires pour encoder une distribution sous forme de code préfixe.
Références
- Cours ECE 255A d’Alon Orlitsky , UCSD
- Cover, T. M., & Thomas, J. A. (2006). Éléments de théorie de l’information. Wiley-Interscience.